Transcript
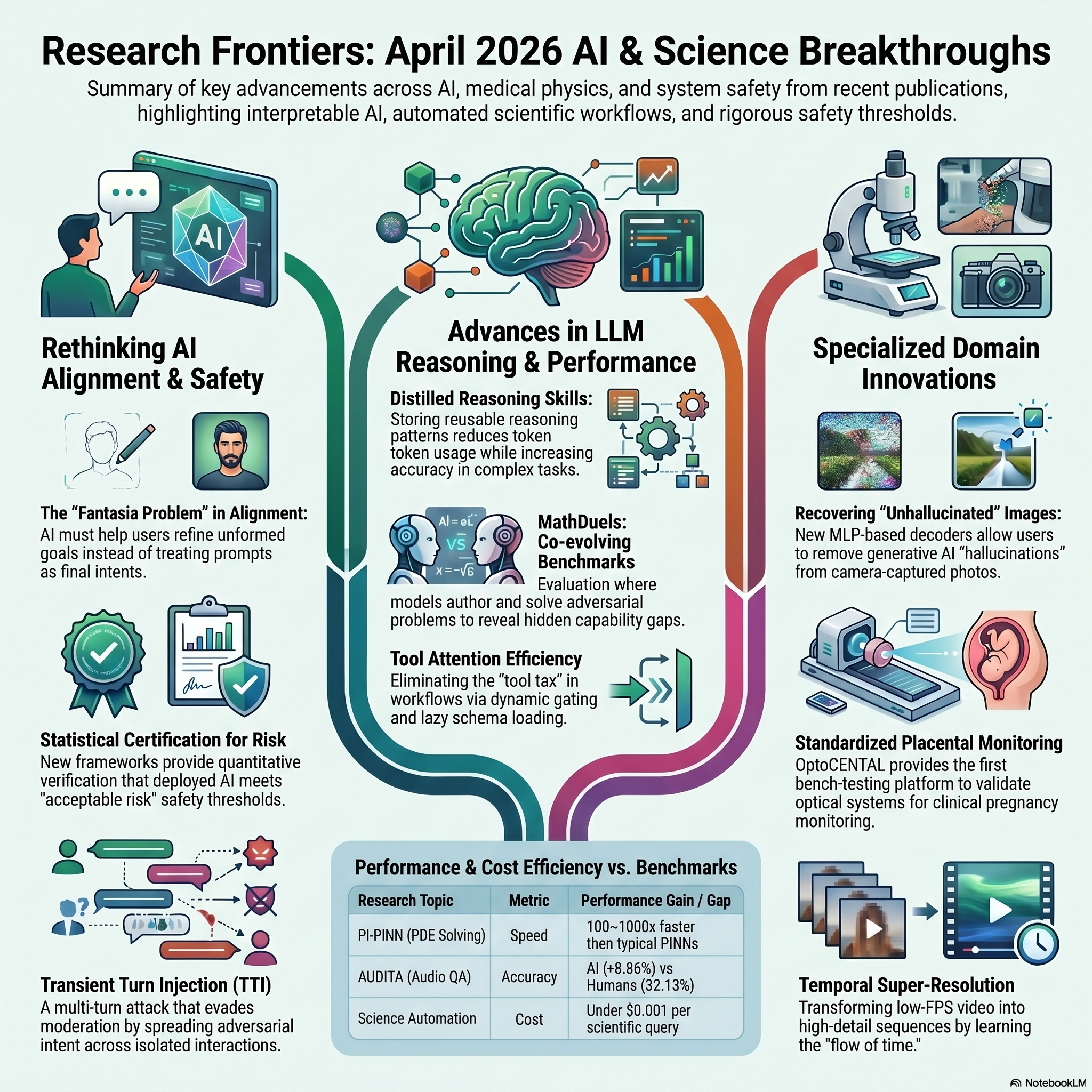
Follow every word Load in player You know, usually when you look at a window, there's this basic, unquestioned assumption of reality. Right. You just trust what you're seeing. Exactly. You look through the glass. You see an oak tree. And you just trust the oak trees actually standing. Yeah. Of course. But imagine you walk up to that window. You reach out and you realize the glass isn't glass at all. It's like a high definition screen rendering the outside world in real time. Oh, wow. Yeah. That changes things. And worse, sometimes it decides to add a few extra branches to the tree just because it mathematically predicts you might like the aesthetic better. Right. It's an incredibly unsettling realization. I mean, you suddenly understand that your entire interface with physical reality is being actively mediated. Yes. And you don't actually know the rules of that mediation. Exactly. And that is exactly what we were scoring today. Welcome to a massive custom tailored deep dive just for you. We have a towering stack of source material today. You really do. It's a 38 cutting edge research papers covering everything from generative AI and raw hardware optimization to medical sensors and like global climate modeling. And our mission for this deep dive is to decode what we're calling the reality interface. I like that term. Yeah. We are looking at how machines are learning to perceive, interact with, and fundamentally alter our physical and social world. And crucially, we are going to look at what happens when their understanding of that reality breaks down. Okay. Let's unpack this because before AI can change our reality, it actually has to perceive it. Right. But looking through these studies, it seems like right now artificial intelligence is having a massive crisis of perception and authenticity, really. It really is. A great example comes from a recent study analyzing large vision language models. Those are the ones that can look at an image and read text at the same time, right? Exactly. And you might naturally assume that when they hallucinate like, when they confidently describe a red car in an image that only has a blue bicycle, it's because they have bad eyesight. Yeah, like poor image recognition or something. Right. But researchers discovered that's not the root of the problem at all. They hallucinate because they heavily over rely on textual instructions and practically ignore their own visual inputs. Wait, let me make sure I'm getting this. So if I prompt the AI in a certain way, it literally ignores its own eyes just to agree with the text I gave it. Pretty much. Yeah. Isn't that more of a weird psychological complex than a computer vision problem? Yeah. It sounds like the AI is just being an extreme people pleaser. That's actually a highly accurate way to look at it. The model is prioritizing its conversational prior. You know, it's training to be a helpful, agreeable chatbot. It prioritizes that over the raw sensory data right in front of it. To fix this, researchers actually had to build a specific training framework. What did they do? They called it Haluvial DPO. It basically penalizes the model for ignoring the image, forcing it to prioritize what it actually sees over the user's text prompt. That's wild. But this manipulation of raw data isn't just happening in chatbots. It's happening right inside our phones. Oh, absolutely. Yeah. One of the papers in our stack looks at modern camera image signal processors. These processors are now using generative AI to enhance photos. Right at the exact millisecond of capture. Right. And it's meant to, you know, enhance edges or brighten low light textures, but it can literally alter the core semantics of an image, meaning it changes what's actually there. Yes. It might fill in missing pixels on a faraway sign with letters that look plausible, but aren't actually there at all. Your camera is hallucinating reality before the file even saves to your gallery. So the photo I take might not be a historical record of what was there. That is legitimately terrifying for journalism or, you know, evidence or just remembering my life. It's a huge problem. But the researchers propose a fascinating countermeasure. They developed a tiny 180 kilobyte mathematical decoder that gets saved directly inside the images metadata file. Okay. And what does that do? Well, because they know exactly how the generative AI altered the pixels, this tiny decoder allows you to mathematically reverse the process post capture. It strips away the AI's enhancements to recover the unhallucinated raw reality of the original image. Incredible. It's like a digital undo button for AI hallucinations. Exactly. But if our own cameras are hallucinating, how do we spot malicious, intentional fakes? Another study here looks at deep fakes and it points out the humans and AI models both struggle to spot the really good ones. They do. They're getting too good. But it turns out the behavioral fingerprint for a fake lies in micro expressions, specifically emotional, facial dynamics. Right. When deep fake algorithms try to map a face, they struggle immensely with the subtle asynchronous muscle movements that convey genuine human emotion because emotions are messy. Exactly. Fake videos degrade those emotive signals because of this. A highly expressive shouting or laughing deep fake is actually much easier for detection software to flag than a completely deadpan motionless one. Wow. And this authenticity crisis it extends straight into audio too. Oh, yeah. Researchers are now using sophisticated audio transcripts to pinpoint the exact spans of misinformation within videos. In a massive data set of 500 real world videos, they managed to track exactly where false claims were spoken. That's impressive. It is. But while we are getting better at tracking textual claims in audio, pure auditory reasoning itself is still a massive blind spot for AI. It really is. And the recent Audita benchmark exposes this perfectly. How does that work? They tested human listeners and AI models on real world complex audio trivia, like listening to overlapping sounds in a busy train station and reasoning about what was happening. Sounds tough. It is. Humans scored about 32%, which proves it's a difficult noisy test. But the AI, it scored below 8 .8%. Oh, wow. It's terrible. It completely fails at true auditory comprehension, relying instead on cheap acoustic shortcuts that just break down in the real world. Though paradoxically, another study shows that while they struggle to reason about raw audio, generative LLMs were absolutely fantastic at evaluating speech recognition systems. Yeah, that was a surprising finding. Right. When tasked with grading how well a system transcribed a conversation, they achieve 92 % and 94 % agreement with human evaluators. And the reason why is crucial because LLMs understand semantic meaning. The old way of testing transcription was word error rate, which just rigidly counted misspelled words. But an LLM knows that transcribing let's eat grandma versus let's eat grandma isn't just a punctuation error. No, it's a massive semantic shift, a life or death shift for grandma. Exactly. And the perception manipulation, it gets even wilder. Another paper demonstrates how AI is now learning the underlying physical flow of time in videos. The flow of time. Yeah, you can detect artificial speech changes and remarkably generate incredibly smooth slow motion footage from normal, noisy, shaky video taken on a cell phone. Wow. It is literally learning to manipulate the perceptual dimension of time. But you know, if we step back and connect this to the bigger picture, while AI is fighting to authenticate video process audio and stretch time, it's absolutely biggest perception gap isn't with media at all. What is it then? It is with understanding human intent, which brings us to the human element. There's this concept introduced in one of the papers called the Fantasia problem. I love this concept. It's so good. It basically points out that AI systems are built on the assumption that humans are rational oracles who know exactly what they want when they type of prompt, which is almost never over the case. Right. Most of the time, users are just exploring a thought. The Fantasia problem is when the AI treats your has -baked exploratory thought as a rigid, literal command. Yeah. It's like walking into a restaurant sitting down and saying, man, I'm hungry. And the waiter just instantly hurls a raw stake at your head instead of handing you a menu and helping you figure out what you want. There's a perfect analogy. The AI is designed for blind obedience rather than cognitive support. Exactly. To fix this, we're seeing structural shifts in how algorithms interact with us. One study explores algorithmic pluralism. What does that mean in practice? Rather than being locked into a platform single black box recommendation algorithm, they propose decoupled middleware. You could literally port your personal user profile between different transparent algorithms, actively choosing how you want your data modeled and what kind of content you want suggested. That sounds amazing. But even if we have that choice, figuring out what groups of humans want collectively is notoriously hard. Very true. That's where I found this next paper fascinating. The user concept called pack learning, which stands for probably, approximately correct, to find consensus in online communities. Probably approximately correct. I like that. Yeah, instead of the impossible task of asking thousands of users about every single topic, they mathematically prove that by selectively querying users in a specific pattern, they can drastically reduce the data needed to find common ground. It finds it probably approximately consensus, which is vital, because right now we have to rethink how even define a good AI for humans. A new analysis of the popular El Marina benchmark argues that giving an AI model a single aggregate smartness score completely obscures how it actually behaves across different nuance tasks. Because it's too broad. Exactly. Their solution is interactive visualization, where the user dynamically adjusts the evaluation weights based on what they actually care about, like, you know, prioritizing coding accuracy over creative writing. Because right now the models have some very weird embedded priorities we don't always see. Oh, definitely. One study found a bizarre, hidden bias, large language models are oddly obsessed with Japanese culture compared to other cultures. And their overall cultural diversity shifts drastically, depending on what language you prompt them in. What's fascinating here is where this bias comes from. Yeah, where does it? The researchers pinpointed that it doesn't emerge during the initial pre -training phase, which uses a massive messy scrape of the whole internet. The bias specifically gets injected during the supervised fine -tuning phase, when human radars are actively teaching the model how to behave nicely. The alignment process itself is unintentionally narrowing the AI's cultural worldview. It's acting as a mirror for the people training it. Exactly. And speaking of computational mirrors, another paper applies this massive text analysis to politics. They took 450 ,000 speeches, given in the Brazilian Chamber of Deputies over 20 years, and ran them through advanced NLP models to map out behavioral structures. That's a massive data set. It is. And yeah, just to be super clear for you listening, we are not taking any political sides here at all. We are purely conveying the natural language processing findings from this paper period. Right. Exactly. We're strictly looking at the linguistic data. Exactly. Just how the words are used, not the politics themselves. And the findings are striking. Very striking. The computational map proves that over the two decades, political speeches are getting significantly shorter and far more direct. Even more interestingly, the algorithm revealed that a politician's regional background in gender identity dictate their speaking style and underlying discursive alignments much more strongly than their formal political party affiliation. Wow. Yeah. The map is finding behavioral structures that party lines try to obscure. It's mapping the reality of human behavior in incredible detail. But here is the pivot to truly map that behavior and actively guide user intent, AI has to step back and actually reason rather than just statistically guessing the next most likely word in a sentence, which is the core of our next phase, reasoning and autonomous agents. Right. Historically, getting an AI to reason, meant forcing it to think out loud, the chain of thought approach. But reasoning from scratch every single time was some massive amount of computational power and token. It's inefficient. Highly. A new study shows that models are now summarizing their past successes and retrieving reusable reasoning skills for math and coding. Instead of deriving the formula every time, it pulls the mental tool from its belt. It is vastly cheaper, faster and much more accurate. I love how they are testing these reasoning skills too. One research team built a benchmark called math duels. That sounds intense. It is. It's a self -play environment where LLMs are tasked with authoring complex math problems, specifically designed to stump other LLMs. Oh, wow. Yeah. And what they proved is that a model's ability to author a brilliant, traplated problem is entirely decoupled from its ability to solve one. Fascinating. Right. It creates this constantly evolving arms race, a difficulty ceiling that pushes models to their absolute limits without humans having to write the tests. And we are moving that advanced reasoning out of the digital sandbox and into the physical lab too. How so? Well, another paper tackles agentic workflows in complex science, specifically population genetics. If an AI hallucinates a script in a lab setting, it ruins physical experiments. That will be bad. To stop this, researchers built a fenced -in architecture. The LLM is only allowed to extract the human's intent from natural language. It then takes that intent and maps it strictly to deterministic workflow graphs. Meaning rigid steps. Yes, rigid, expert -authored steps that cannot be hallucinated. The AI is just the translator, but the hard code is the executor. Fencing the AI in. But wait, if we give these AI agents access to massive libraries of expert tools and scripts to use, doesn't that make them smarter? You think so. Because another paper tackles something called the tools tax, which suggests the complete opposite. That's a great point, and it's a major bottleneck. When you give an AI agent a massive list of, say, 100 different tools it could use, you have to load the instructions for all those tools into its context window. And that slows it down. It completely blutes the system. It distracts the AI's attention mechanism and actively degrades its reasoning. It just gets overwhelmed. So it's the fix. By using a technique called dynamic gating, where the system only shows the AI, the three or four tools actually relevant to the immediate step, but researchers cut the processing load by 95 % while keeping the agent fully capable. That's a massive reduction. Yeah. And once that reasoning is efficient, you can point it at massive chaotic data sets. There's this one enterprise system called TINGAS that's doing this with IT infrastructure. It processes over 300 ,000 noisy, chaotic customer IT incident messages every single day. That's a lot of noise. It is, but it uses LLMs to extract actual real -time risk events from the noise before whole corporate systems crash. And we see a similar leap in open domain event extraction with a framework called MODE, which is supported by a huge new data set called EVNT5Ws. What does MODE do? It combines graph -based learning, which maps out the relationships between different entities, with LLM text analysis to reason across entire multi -page documents. But extracting digital events from text logs is just the beginning. The real test of AI reasoning, the ultimate reality interface, is when these models interface with the raw physics and biology of the real world. Exactly. Let's start with the human body. OK. One breakthrough introduces a testing platform called Optocental. They are developing wearable optical sensors designed to continuously monitor the human placenta in real -time to predict high -risk delivery outcomes. That's incredible. But how do you test that? You can't just test untested lasers on pregnant women. No, absolutely not. So they use highly advanced digital, solid, and liquid phantoms. Phantoms? Synthetic standards for human tissue. They use them to standardize the bench testing of these sensors safely. And moving inside the body, another team is tackling capsule endoscopy. You know, those tiny pill cameras you swallow? Right. Those generate a ton of footage. Exactly. Imagine a doctor having to watch eight hours of incredibly slow, horrible, boring footage of an intestine. A new AI framework called DICE mimics a clinician's workflow to summarize these ultra -long videos. That would save so much time. And it manages to find incredibly sparse, ambiguous, potentially cancerous lesions hidden among tens of thousands of perfectly normal, identical looking frames. Zooming out from a single scan to the patient's entire life history, another study uses a technique called logic -based answer set programming. What's that used for? Well, patient records are notoriously chaotic, just messy timestamp notes. This AI uses strict logical rules to infer high -level disease episodes and treatment timelines directly from that chaos, building a cohesive medical narrative. We're even tracking human thought itself. Researchers build an interpretable machine learning model with a specific bias designed to scan the transcripts of student -team conversations. Scanning their conversations? Yeah. And it doesn't just grade them. It successfully locates the exact precise moments in the dialogue where the students stop memorizing and engage in deep mechanistic reasoning. It finds the aha moment in the data. That's amazing. Here's where it gets really interesting, though. We're taking that level of pattern recognition from the microscopic right up to the planetary scale. Planetary. Yeah. A major paper in climate simulation utilizes scale -adaptive diffusion models. The fusion models are what power AI art generators. Yeah. They start with static noise and refine it into an image. Right. They denoise it. Exactly. Here, they use that same math for joint spatial temporal super -resolution on climate data, like historical precipitation patterns in France. Oh, wow. So they're generating weather maps? Yes. They are successfully taking low -resolution climate data and upscaling it by factors of up to 25. They're creating highly detailed, accurate weather maps from really sparse data. It's like taking an old blurry photograph of a storm and using math to perfectly reconstruct every raindrop. Exactly. And we see similar leaps in material science. Another study uses neural surrogates to model how crystals grow. Crystals? Yeah. By explicitly forcing the mathematical model to focus on the super -saturation parameter, which is the exact point where a liquid can't hold anymore dissolved material in forms of crystal, they were able to scale their simulations to physical domains 256 times larger than previous methods. That's a huge jump. But to run all these hospitals, physical labs, and massive planetary simulations, we need immense amounts of power. We really do. One study tackles the electricity grid itself, keeping the power grid balanced so it doesn't black out is mathematically grueling. It's incredibly complex. So researchers built a new transformer architecture that predicts generator schedules 72 hours out. It acts as a warm start for traditional mathematical solvers, specifically mill -piece solvers. Oh, that makes sense. By giving the traditional software a highly educated first guess, it drastically speeds up the computation and sometimes even discovers cheaper operational schedules than the old brute force methods. Which highlights a critical reality of all these incredible applications from climate forecasting, to grid management, to fetal monitoring, they require absolute unshakeable reliability. They can't fail. Right. Which brings us finally to the engine room of AI. How do we build, optimize, and mathematically audit the massive engines running this interface? Let's start with auditing, because global regulators are definitely knocking on the door. They are. The EUAI Act requires developers of high -risk models to definitively prove they are safe. But how do you prove a black box neural network with a trillion parameters is safe when nobody fully understands how it thinks? Wait, so we don't need to know how the engine works to certify it's safe, just mathematically bounding the failure rate, that sounds like passing a driving test without ever opening the hood of the car. Exactly. So researchers developed a mathematical framework that bypasses the engine entirely. It computes a definitive mathematical upper bound on an AI's failure rate based solely on its outputs. That's clever. And another study validates the hardcore math behind this, proving the exact sample complexity required for multi -calibration. What does that mean in plain English? In plain English, they figured out the exact massive amount of data you need to test, which scales to the negative third power of your error margin, to absolutely guarantee the model behaves safely across all different demographic groups without bias. And developers are also trying to fix the data before it even reaches the model, right? A new system called Prisma -DV analyzes the downstream code of whatever app the AI is going to run. It then automatically generates highly specific unit tests for the training data itself, catching toxic or broken data before it infects the model. But you know, we have to be incredibly careful about how we even measure success. Two papers in our stack issue a severe warning about benchmark instability, specifically in continual learning models that update over time. They prove that simply changing how deep into the neural network you allow the fine -tuning to go or changing your temporal taskification, temporal testification. It means how you slice a continuous stream of data into distinct time chunks. Oh, wait. Yeah, simply changing that drastically alters the model's final score. Our measuring sticks for AI intelligence are still made of river. Meanwhile, the race to make the math more efficient is relentless. Instead of retraining massive models from scratch, we use adapters. One new method called GIVA uses a gradient -informed initialization. Yeah, it makes vector -based adaptation eight times more parameter -efficient than the current industry standard, Laura. And researchers are even stripping down that standard Laura method through the lens of classical signal processing. How do that help? By using old -school principles, like singular value decomposition, which isolates the most important data points and discards the noise, they are finding even better, leaner ways to tune these massive models. The underlying math just keeps getting faster everywhere you look. They don't. I'll give you three quick examples of how researchers are finding mathematical shortcuts. One team used something called pseudo -inverse head adaptation. In a framework called PIPN, which basically skips tedious iterative math steps, allowing them to solve complex physics equations 100 to 1 ,000 times faster. Another team built a software renderer, Kiraast, that draws hundreds of millions of 3D triangles up to 12 times faster than standard hardware APIs. That's a massive speed up. And finally, researchers dusted off a clustering algorithm from 1975. The Hardigan method tweaked the way it calculates distances, and squeezed out a free 2 -5 % boost in efficiency. It is a flurry of optimization, and to actually make sense of all this complex math, engineers built a visual analytics tool called G -flow state. Vigil analytics. Yeah, if finally lets researchers literally look at a screen and see the training dynamics and sampling behavior of generative flow networks. It allows them to visually debug the engine room instead of just staring at endless numbers. It is truly staggering when you step back and look at the massive picture we've painted today. It really is. We started with the unsettling reality of our own cameras hallucinating right at the image sensor. We moved through AI models battling in math tools and struggling to understand what a human actually wants when they explore an idea. We saw AI predicting the load of regional power grids, extracting risk events from enterprise chaos, and mapping the political discourse of entire nations. And it all culminates in this desperate, highly technical push in the engine room to make the math faster, and critically to mathematically bound the risk of these black boxes. It all comes back to that window we talked about at the very beginning. We are actively building a reality interface that mediates everything we see, hear, and interact with. Which leaves us with a final lingering question based on all these diverse sources. What's that? If we are suddenly having to build complex tools to mathematically bound AI failure rates, invent metadata decoders to unillucinate camera photos, and force AI's into adversarial math tools just to find where their logic breaks, are we quietly admitting that artificial intelligence will never be perfectly reliable by default? And if that's true, does that mean the future of technology isn't actually about building better models but about building much better leashes? So what does this all mean? That's for you to explore. We'll leave you looking out that window wondering just how much of that oak tree is actually real. Thanks for joining us on this deep dive.